AIの成績表?AIベンチマーク「GAIA」
- 2024.02.25
- AI

旧FadebookのMetaとHuggingFaceは共同で、2023年11月23日、新たなAIのベンチマークとして「GAIA」を発表しました。
Googleによる日本語翻訳
GAIAは、人間にとって簡単なタスクを達成する大規模言語モデル(LLM)を評価することを目的としています。従来のAIベンチマークは、人間にとって困難なタスクを対象としており、LLMには数学や法律などの複雑なタスクや、一貫性のある本を書くなどの複雑な課題が課せられています。
GAIAとは
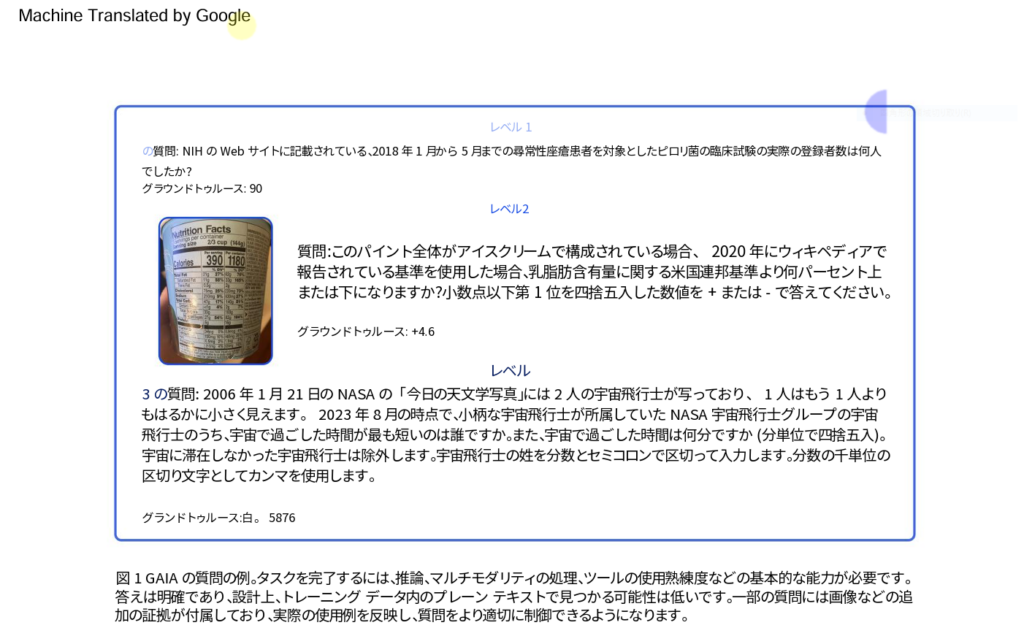
GAIAには、466の綿密な質問とその解答が含まれており、3段階の難易度で構成されています。これらの質問はテキストベースであり、ときにはファイル(画像やスプレッドシートなど)も含まれます。質問の数量は少ないが、内容は厳選されています。質問は短く、単一の回答を求めるように設計されているため、検証が容易です。
- 400を超える多様なタスクが含まれる。タスクには自然言語処理、論理推論、知識推論などがある。
- 人間レベルの一般的な能力を測定することを目的としている。
- 安全性と有用性の両方を評価する。例えば、有害な返答を避ける能力などをテストする。
- 大規模で高性能な言語モデルの評価に適している。
- 定期的にタスクが更新され、モデルの進歩に合わせて難易度が上がっていく。
- 結果はleaderboardで公開され、様々なモデルを比較できる。
GAIAの目的 人が答えられる問題のスコア
GAIAは、人間にとって簡単なタスクを達成するLLMを評価することを目的としています。GAIAの質問は、非専門家の人間でもほぼ完璧なスコアが出せるほどシンプルで、主にWebなどさまざまな情報源から情報を探し出し、変換して正確な回答を生成して構成しています。
汎用人工知能 (AGI) の進化を測定・評価すること
GAIAは、言語、推論、知識などの一般的な認知能力を測る多様なタスクを含んでいます。これにより、AGIの進展と全体的な能力を評価できます。
AGIの安全性と有用性を評価すること
GAIAでは、単に性能だけでなく、有害な返答の回避、説明能力、不確実性の推定など、安全性と有用性に関する特定のメトリクス(定評化した指標)も用意されています。
GAIAの特徴 自動化/3段階/オープンソース
人間にとって簡単なタスクを対象とする
GAIAは、人間にとって簡単なタスクを達成するLLMを評価することを目的としています。GAIAの質問は、非専門家の人間でもほぼ完璧なスコアが出せるほどシンプルで、主にWebなどさまざまな情報源から情報を探し出し、変換して正確な回答を生成して構成されています。
自動化された評価方法を採用する
GAIAの評価は、自動化され、迅速かつ事実に基づくように設計されています。実際には、各質問に対して、文字列(一語または数語)、数値、または、文字列や浮動小数点数のコンマ区切りのリストといった回答が求められます。そして、正しい答えは1つだけです。
3段階の難易度で構成される
GAIAの質問は、3段階の難易度で構成されています。レベル1は最も簡単なタスクであり、レベル3は最も難しいタスクです。これにより、LLMの性能をより細かく評価することができます。
オープンソースで公開されている
GAIAは、オープンソースで公開されています。これにより、研究者はGAIAを自由に利用して、LLMの研究開発を進めることができます。
その他の特徴
- 400以上の多様なタスクが含まれる:自然言語処理、論理推論、数学的推論、知識推論など多岐にわたる
- 大規模言語モデルに適したベンチマーク設計:GPT-3など大規模モデルの能力評価に適している
- タスクが定期的に更新され難易度が上がる:モデルの進化に合わせて継続的に難易度が上げられる
GAIAは、これらの特徴により、AIの研究開発において重要な役割を果たす可能性があります。
GAIAの構成・流れ
汎用AIの評価プラットフォームとして必要となる項目です。
| タスクセット | 400以上の多様なタスクから構成される 自然言語処理、論理推論、数学的推論、知識推論などのタスクが含まれる |
| メトリクス | 性能:タスクごとの正解率や適合率など 安全性:有害な返答の回避率、説明の質など 有用性:不確実性の推定精度、人間の満足度など |
| データセット | 各タスクに対応した大規模なデータセット ウィキペディアやBookCorpusなどの大規模コーパスも利用 |
| モデル評価環境 | 参加モデルのAPIエンドポイントを設定 自動的にタスクデータを提示し返答を評価 |
| リーダーボード | 性能、安全性、有用性のメトリクスを公開 様々なモデルの比較・分析が可能 |
スクロールできます
上記の要件を満たす為、GAIAは次の4つの要素で構成されています。
1.質問
GAIAには、466の綿密な質問とその解答が含まれており、3段階の難易度で構成されています。これらの質問はテキストベースであり、ときにはファイル(画像やスプレッドシートなど)も含まれます。質問の数量は少ないが、内容は厳選されています。質問は短く、単一の回答を求めるように設計されているため、検証が容易です。
2.回答
GAIAの質問には、正しい回答が1つだけあります。正しい回答は、テキスト、数値、または文字列や浮動小数点数のコンマ区切りのリストで構成される場合があります。
3.評価方法
GAIAでの評価は自動化され、迅速かつ事実に基づくように設計されています。実際には、各質問に対して、文字列(一語または数語)、数値、または、文字列や浮動小数点数のコンマ区切りのリストといった回答が求められます。そして、正しい回答と比較して評価されます。
4.スコアリング
GAIAのスコアは、各質問の正解率に基づいて算出されます。スコアは0から100の範囲で表され、スコアが高いほど、LLMの性能が高いことを意味します。
具体的には、次の手順で評価が行われます。
- LLMに質問を投げかけ、回答を生成させる。
- 生成された回答を、正しい回答と比較して評価する。
- 各質問の正解率に基づいてスコアを算出する。
GAIAは、オープンソースで公開されているため、研究者はGAIAを自由に利用して、LLMの研究開発を進めることができます。
GAIAの評価方法
評価の自動化
GAIAの評価の自動化とは、人の手を介さずにAIシステムの能力を定期的に評価する仕組みのことを指します。
具体的には以下のような方法が取られています。
- 参加するAIはAPIエンドポイントを実装する
- GAIAはそのAPIに対して自動的に入力データを送信し、返答を評価する
- 大規模な事前処理済みの入力データセットを活用する
- 毎日または毎週、最新モデルの評価を自動で実行する
- 評価に必要なコードは共有し、追加や拡張を容易にする
- 結果はリーダーボードにリアルタイム表示し、比較できるようにする
このようにGAIAでは、人手を介さずに継続的かつ大規模にAIモデルの評価を自動で行う仕組みが構築されています。これにより評価の効率性と安全性確保が可能になります。評価の自動化はGAIAの大きな特徴の一つです。
評価の迅速性
GAIAの評価の迅速性とは、AIシステムの能力をできるだけ速やかに評価し、結果を反映できるようにするための工夫のことを指します。
具体的には以下のような方法が採用されています。
- APIベースで実装することでいつでも評価可能にする
- クラウドコンピューティングを活用して並列評価を高速化する
- 事前に入力データを処理しておき、即座に提供できるようにする
- 評価の計算処理の順序や方法を最適化する
- 新しいモデルはすぐに評価対象に追加する
- 評価結果はリアルタイムでリーダーボードに反映させる
このようにGAIAでは、評価自体の効率化だけでなく、評価プロセス全体を高速かつ効果的にする工夫がされています。
これにより、AIシステムの能力の変化や改善を素早く検知し、タイムリーに対応することが可能になります。評価の迅速性はGAIAの重要な特徴の一つです。
評価の客観性
GAIAの評価は、正誤判定に基づいて自動化されているため、評価結果に主観的な判断が入り込む可能性は低いとされています。ただし、完全に客観的な評価を行うことは不可能であり、GAIAの評価においても、客観性を高めるための取り組みが継続されています。
GAIAの評価の客観性を高めるための取り組みとしては、次のようなものが挙げられます。
- 評価対象の質問を簡潔にすること
GAIAの質問は、3段階の難易度で構成されており、それぞれに100以上の質問が用意されています。各質問は、文字列(一語または数語)、数値、または、文字列や浮動小数点数のコンマ区切りのリストといった回答が求められます。そして、正しい答えは1つだけです。
これらの質問は、単純で明確に書かれており、評価対象のLLMの性能を正確に評価できるように設計されています。
- 評価方法を自動化すること
GAIAの評価は、正誤判定に基づいて自動化されています。具体的には、LLMが生成した回答を、正しい回答と比較して、正解か不正解かを判定します。
この評価方法により、人間による評価に比べて、主観的な判断が入り込む可能性を低減することができます。
- 評価結果の分析
GAIAの評価結果は、統計的な手法を用いて分析されます。この分析により、評価結果に偏りがないかを検証することができます。
GAIAの評価の客観性を高める取り組みは、今後も継続される予定です。
GAIAの限界 再現性/劣化/コスト/汎用性
評価プロセスの再現性
GAIAの評価プロセスの再現性とは、同じ条件で評価を行った場合、同じ結果が得られるかどうかということです。
GAIAの評価プロセスの再現性を高めるためには、次の2つのポイントが重要です。
- 評価対象の質問を標準化すること
GAIAの質問は、3段階の難易度で構成されており、それぞれに100以上の質問が用意されています。各質問は、文字列(一語または数語)、数値、または、文字列や浮動小数点数のコンマ区切りのリストといった回答が求められます。そして、正しい答えは1つだけです。
これらの質問は、単純で明確に書かれており、評価対象のLLMの性能を正確に評価できるように設計されています。また、質問の難易度や回答の形式は、すべて標準化されています。
- 評価方法を標準化すること
GAIAの評価は、正誤判定に基づいて自動化されています。具体的には、LLMが生成した回答を、正しい回答と比較して、正解か不正解かを判定します。
この評価方法は、すべて標準化されています。また、評価結果の分析も、統計的な手法を用いて標準化されています。
これらの標準化により、同じ条件で評価を行った場合、同じ結果が得られる可能性が高まります。
GAIAの評価プロセスの再現性は、評価結果の信頼性を高めるために重要な要素です。そのため次のような取り組みがあります。
- 質問の難易度や回答の形式の検証:GAIAの質問の難易度や回答の形式が、適切に設計されているかどうか
- 評価方法の検証:GAIAの評価方法が、適切に設計されているかどうか
- 評価結果の分析方法の検証:GAIAの評価結果の分析方法が、適切に設計されているかどうか
これらの取り組みにより、GAIAの評価プロセスの再現性をさらに高めていくことを目指しています。
質問の劣化
「質問の劣化」とは、GAIAの質問が、時間の経過とともに、LLMの性能を正しく評価できなくなることを指します。
具体的には、次の2つの原因が考えられます。
- LLMの性能の向上
LLMの性能が向上すると、LLMは、より難しい質問にも正しく回答できるようになります。そのため、以前は正解だった回答が、現在では不正解になる可能性があります。
- 質問の難易度の変化
GAIAの質問は、時間の経過とともに、新しい知識や技術が反映されることで、難易度が変化する可能性があります。そのため、以前は適切な難易度だった質問が、現在では難しすぎる、または簡単すぎる可能性があります。
質問の劣化を防ぐための取り組みとして、次のようなものが挙げられます。
- 質問の定期的な更新
GAIAの質問は、定期的に更新され、新しい知識や技術が反映されています。これにより、質問の難易度が変化するリスクを軽減することができます。
- 質問の難易度の評価
GAIAの質問は、定期的に評価が行われ、適切な難易度になっているかどうかが検証されています。これにより、質問の難易度が不適切になっているリスクを軽減することができます。
これらの取り組みにより、GAIAの質問の劣化を防ぎ、評価結果の信頼性を高めていくことを目指しています。
GAIAでは以下のような対策が取られています。
- 質問データセットを大規模に用意し、容易に枯渇しないようにする
- 質問の提示順序をランダム化し、特定のパターンで学習しにくくする
- 定期的に新しい質問を追加し、学習をリセットする
- 同じ質問に対する回答の一貫性を評価指標に入れる
- モデルに対する「教育」を禁止し、本来の能力を測定する
- 人間評価者によるサンプリングチェックを実施する
このように、質問データの管理、提示方法の工夫、新しい指標の導入などにより、GAIAでは質問の劣化が生じにくい評価設計が行われています。これによりAIシステムの真の実力を測定できるとされています。
質問設計のコスト
GAIAにおける「質問設計のコスト」とは、多様で質の高い質問データセットを作成するために必要なコストのことを指します。
具体的には、以下のようなコストが発生します。
- 質問と正解データの人手作成コスト
- 質問データのレビューや検証のコスト
- 多様な分野の専門家による質問設計コスト
- 質問データの継続的な追加や更新のコスト
- 大規模な質問データセットのストレージと管理コスト
- 質問提示システムの開発・運用コスト
GAIAでは、クラウドとクラウドソーシングを活用することで、これらのコストをある程度抑えています。
しかしながら、人間レベルの質問設計には依然として多大なコストがかかっており、これがGAIAの課題の1つとされています。質問設計プロセスの自動化や効率化が期待されています。
言語と文化の多様性の欠如
GAIAにおける「言語と文化の多様性の欠如」とは、GAIAの質問データや評価対象が英語を中心とした限られた言語・文化に偏っていることを指します。
具体的な問題点は以下の通りです。
- 質問データが英語中心で、他言語の割合が小さい
- 文化的背景がアメリカ・西欧中心である
- 英語以外の言語能力を測定できていない
- 文化的多様性に対応した汎用的な知能が評価できていない
これらはGAIAの目標である「汎用人工知能」の評価としては限界の問題点だと言えます。
GAIAでは今後、翻訳タスクの追加や多言語データの拡充、非西欧圏の専門家を含めた質問設計などの取り組みにより、言語と文化の多様性を高めることが課題とされています。
まとめ
GAIAの重要性
GAIAが重要視される主な理由は以下の点です。
- 汎用AIの進化を測定できる:言語、推論、知識など多角的な能力を評価
- 安全性と有用性も評価対象:性能だけでなく安全性確保のために必要
- 大規模言語モデルの能力検証に適している:GPTなど最新のモデルを評価できる
- 継続的なベンチマークとして機能:タスクと評価基準が進化するよう設計されている
- AGI開発コミュニティの標準的ベンチマークになりうる:多くの組織が参加しやすいオープンな設計
- 産業応用における基準を提供できる:実運用するAIの性能と安全性を測定できる
このように、GAIAは汎用AIの進歩を促進し、安全性を担保する上で欠かせないインフラとなる可能性があるため、その意義は大きいと考えられています。
今後、AIが社会に浸透するほどに、GAIAの重要性も増していくのかもしれません。
-
前の記事

アメリカがAI規制導入とそこから見えるAIの重心 2024.02.20
-
次の記事
敵対的生成ネットワーク:GAN(Generative Adversarial Networks)ってなに 2024.02.25