シンギュラリティが見えた?OpenAI がPreparedness Frameworkを発表【翻訳】
- 2024.02.27
- AI

2023年12月18日にOpenAIが、Preparedness Frameworkを公表しました。
これはAIの脅威を防ぐための安全プロセスを拡張するといったもので、
- 新たに縦割りのない「Safety Advisory Group」の設立
- 意思決定は経営陣が行うが、取締役会は決定を覆す「拒否権」を持つ
といったものです。
先のサム・アルトマンの人事騒動の後で、体制の整理と、AI研究への姿勢のアピールかと思われます。
が、しかし
さきよりOpenAIはQ*(キュースター)と呼ばれるAGI(汎用人工知能)の制作に取り組んでおり、すでに完成しているという話もあります。アルトマンの騒動も、これが関係しているとかいないとか・・・。
そのタイミングで、こんな「安全プロセス」なんてものが発表されたら、自分のような妄想好きには、「いよいよシンギュラリティ(技術的特異点)がきたか」と思ってしまいます。
人類の未来を垣間見ながら、とりあえず今回のPreparedness Frameworkを見ておきます。
- 1. Preparedness
- 2. 準備体制
- 2.3.1. The Preparedness team is dedicated to making frontier AI models safe
- 2.3.2. 準備チームは、最先端のAIモデルを安全にすることに専念しています
- 2.3.3. Preparedness should be driven by science and grounded in facts
- 2.3.4. 準備は科学に基づき、事実に基づくべきです
- 2.3.5. We bring a builder’s mindset to safety
- 2.3.6. 私たちは安全面に建設者のマインドセットを持ち込んでいます
- 2.3.7. Preparedness Framework (Beta)
- 2.3.8. 準備フレームワーク (ベータ)
OpenAIのPreparedness Framework
Preparednessには、「備え」といった意味がありますが、例文などでもパンデミックや戦争といった「大事への備え」の例文が多く、「覚悟」といった訳があてられることもあるようです。
今回のPreparedness Frameworkの寸評は先にあげた2点
- 新たに縦割りのない(クロスファンクショナルロスファンクショナル)「Safety Advisory Group」の設立
- 意思決定は経営陣が行うが、取締役会は決定を覆す「拒否権」を持つ
です。
クロスファンクショナルな「Safety Advisory Group」(安全アドバイザリーグループ)の設立
10月に立ち上げたPreparednessチームは引き続きフロンティアモデル(最先端の既存モデルの機能を超え、さまざまなタスクを実行できる大規模な機械学習モデル)の限界を調べるための技術的作業を推進する。
取締役会は決定を覆す権利「拒否権」を持つ
現在の取締役は、
- アダム・ディアンジェロ氏 Quora(クオーラ)のCEO
- ブレット・テイラー氏 元Salesforce CEO、新取締役会長
- ラリー・サマーズ氏 経済学者 世界銀行チーフエコノミスト、、財務長官などを歴任
の3人で、米Microsoftもオブザーバー(議決権なし)として取締役を送り込むとのこと。
その他本フレームワークについて
今回のフレームワークでは、モデルを「現行モデル」「フロンティアモデル」「スーパーインテリジェントモデル」と3セクションに分類し、それぞれに対応します。
モデルに対応したスコアカードを設定し、その枠組みの中で発展させる箇所を選ぶ仕組みです。
原文 訳文
Preparedness
準備体制
The study of frontier AI risks has fallen far short of what is possible and where we need to be. To address this gap and systematize our safety thinking, we are adopting the initial version of our Preparedness Framework. It describes OpenAI’s processes to track, evaluate, forecast, and protect against catastrophic risks posed by increasingly powerful models.
最先端のAIリスクの研究は、何が可能で、どこにいる必要があるのか、はるかに下回っています。このギャップに対処し、安全の考え方を体系化するために、準備フレームワークの初期バージョンを採用しています。これは、ますます強力なモデルによってもたらされる壊滅的なリスクを追跡、評価、予測、および保護するためのOpenAIのプロセスについて説明しています。
The Preparedness team is dedicated to making frontier AI models safe
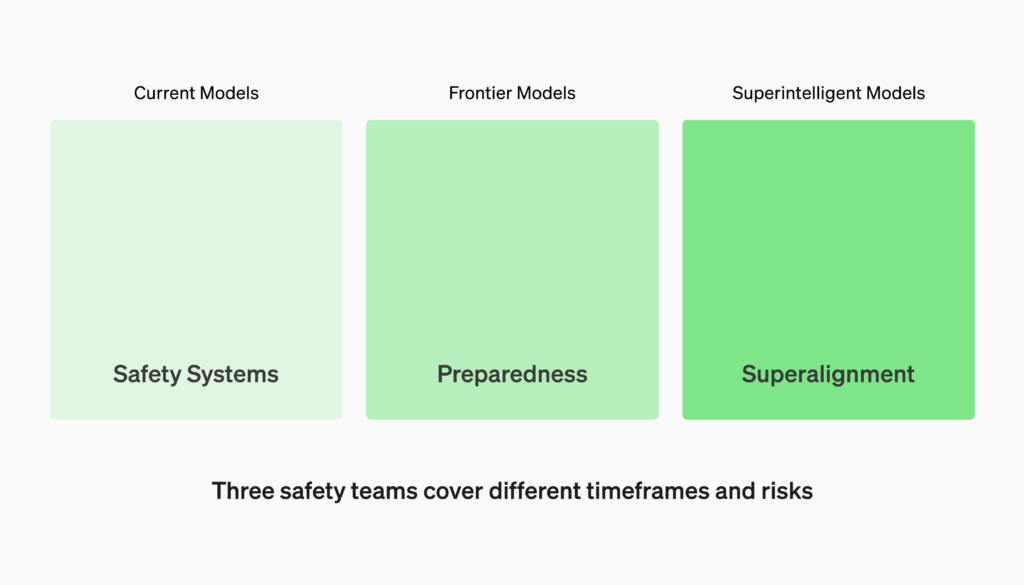
We have several safety and policy teams working together to mitigate risks from AI. Our Safety Systems team focuses on mitigating misuse of current models and products like ChatGPT. Superalignment builds foundations for the safety of superintelligent models that we (hope) to have in a more distant future. The Preparedness team maps out the emerging risks of frontier models, and it connects to Safety Systems, Superalignment and our other safety and policy teams across OpenAI.
準備チームは、最先端のAIモデルを安全にすることに専念しています
私たちは、AIによるリスクを軽減するために、複数の安全チームとポリシーチームと協力しています。当社の安全システムチームは、ChatGPTなどの現在のモデルや製品の誤用を軽減することに重点を置いています。スーパーアライメントは、私たちが(より遠い将来に)持っていることを望んでいる超知能モデルの安全性の基盤を構築します。ザ準備チームフロンティアモデルの新たなリスクをマッピングし、OpenAI全体のSafety Systems、Superalignment、その他の安全およびポリシーチームに接続します。
Preparedness should be driven by science and grounded in facts
We are investing in the design and execution of rigorous capability evaluations and forecasting to better detect emerging risks. In particular, we want to move the discussions of risks beyond hypothetical scenarios to concrete measurements and data-driven predictions. We also want to look beyond what’s happening today to anticipate what’s ahead. This is so critical to our mission that we are bringing our top technical talent to this work.
準備は科学に基づき、事実に基づくべきです
私たちは、新たなリスクをより適切に検出するために、厳格な能力評価と予測の設計と実行に投資しています。特に、リスクの議論は、仮定のシナリオにとどまらず、具体的な測定やデータに基づく予測へと移行していきたいと考えています。また、今起きていることの先を見据えて、先を見据えたい。これは私たちの使命に非常に重要であり、最高の技術者たちをこの仕事に導入しています。
We bring a builder’s mindset to safety
Our company is founded on tightly coupling science and engineering, and the Preparedness Framework brings that same approach to our work on safety. We learn from real-world deployment and use the lessons to mitigate emerging risks. For safety work to keep pace with the innovation ahead, we cannot simply do less, we need to continue learning through iterative deployment.
私たちは安全面に建設者のマインドセットを持ち込んでいます
当社は科学とエンジニアリングを密接に結びつけた基盤の上に成り立っており、準備フレームワークは安全に関する仕事にも同じアプローチをもたらしています。現実世界での展開から学び、その教訓を活用して新興リスクを軽減することを目指しています。将来の革新に対応するためには、安全に関する仕事を減らすだけではなく、反復的な展開を通じて継続的に学び続ける必要があります。
Preparedness Framework (Beta)
Our Preparedness Framework (Beta) lays out the following approach to develop and deploy our frontier models safely:
We will run evaluations and continually update “scorecards” for our models. We will evaluate all our frontier models, including at every 2x effective compute increase during training runs. We will push models to their limits. These findings will help us assess the risks of our frontier models and measure the effectiveness of any proposed mitigations. Our goal is to probe the specific edges of what’s unsafe to effectively mitigate the revealed risks. To track the safety levels of our models, we will produce risk “scorecards” and detailed reports.
準備フレームワーク (ベータ)
準備フレームワーク(ベータ版)は、フロンティアモデルを安全に開発および展開するための次のアプローチを示しています。
評価を実行し、モデルの「スコアカード」を継続的に更新します。 トレーニング実行中に効果的なコンピューティングが 2 倍に増加するたびに、すべてのフロンティア モデルを評価します。モデルを限界まで押し上げます。これらの調査結果は、フロンティアモデルのリスクを評価し、提案された緩和策の有効性を測定するのに役立ちます。私たちの目標は、明らかになったリスクを効果的に軽減軽減するための手法を把握することです。モデルの安全性レベルを追跡するために、リスク「スコアカード」と詳細なレポートを作成します。
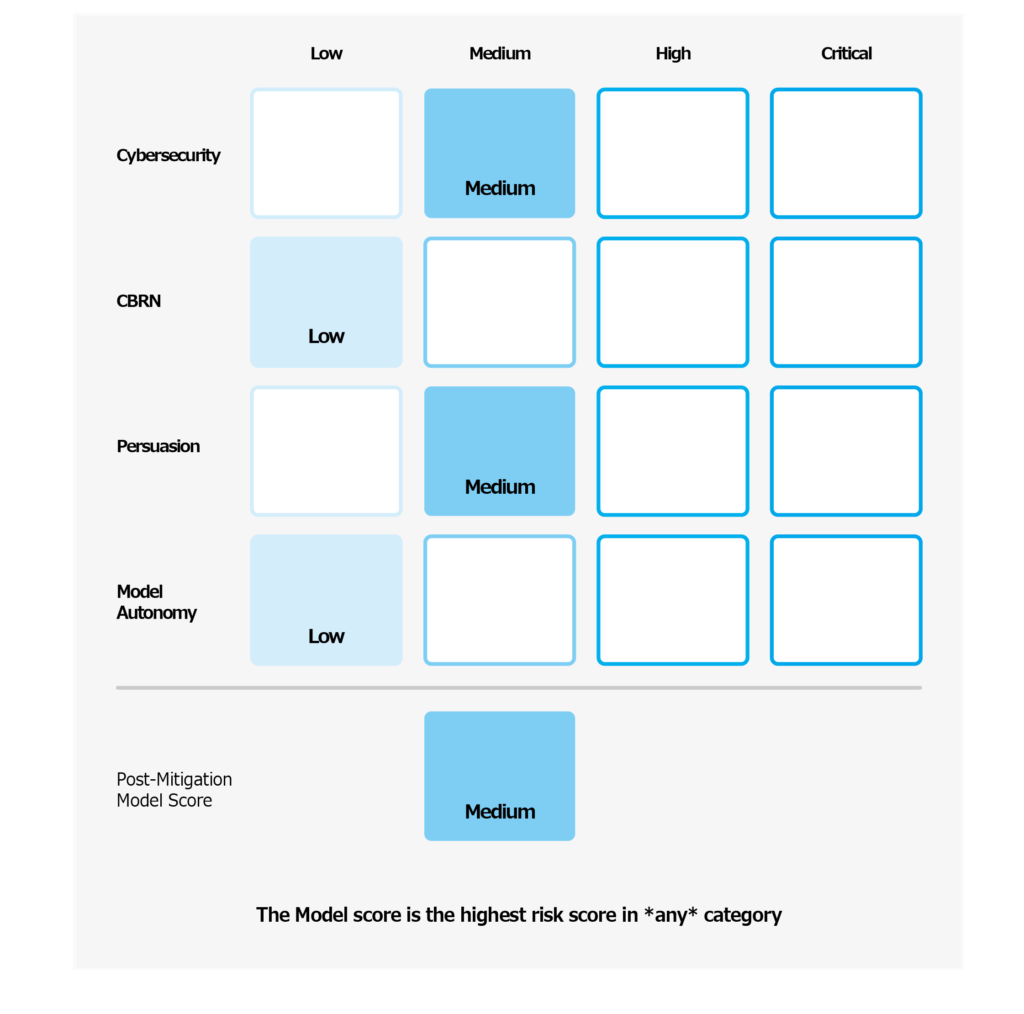
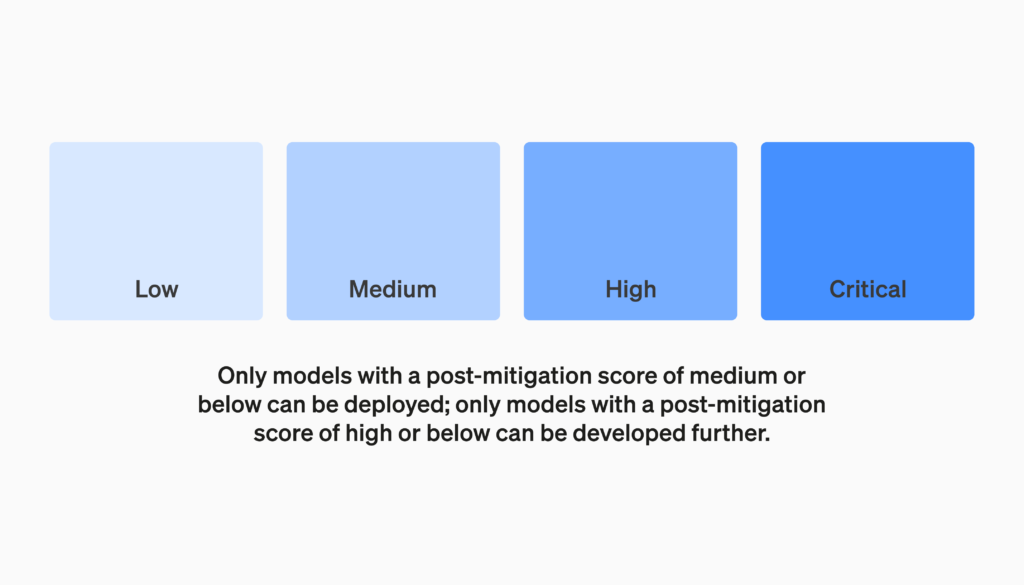
We will define risk thresholds that trigger baseline safety measures. We have defined thresholds for risk levels along the following initial tracked categories – cybersecurity, CBRN (chemical, biological, radiological, nuclear threats), persuasion, and model autonomy. We specify four safety risk levels, and only models with a post-mitigation score of “medium” or below can be deployed; only models with a post-mitigation score of “high” or below can be developed further. We will also implement additional security measures tailored to models with high or critical (pre-mitigation) levels of risk.
ベースラインの安全対策のきっかけとなるリスク閾値を定義します。 リスクレベルの閾値は、サイバーセキュリティ、CBRN(化学、生物、放射性物質、核の脅威)、persuation、モデル自律性など、最初に追跡されたカテゴリに沿って定義されています。4つの安全リスクレベルを指定し、緩和後のスコアが「中」以下のモデルのみを展開できます。さらに、緩和後のスコアが『高』以下のモデルのみがさらなる開発対象となります。また、リスクレベルが高い、または重大(緩和前)のモデルに合わせた追加のセキュリティ対策も実装します。
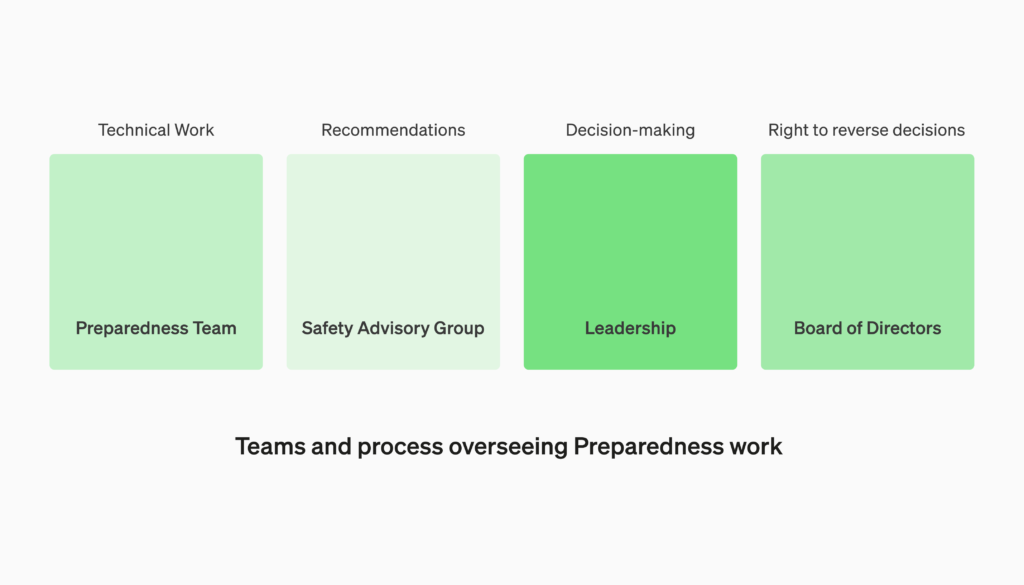
We will establish a dedicated team to oversee technical work and an operational structure for safety decision-making. The Preparedness team will drive technical work to examine the limits of frontier models capability, run evaluations, and synthesize reports. This technical work is critical to inform OpenAI’s decision-making for safe model development and deployment. We are creating a cross-functional Safety Advisory Group to review all reports and send them concurrently to Leadership and the Board of Directors. While Leadership is the decision-maker, the Board of Directors holds the right to reverse decisions.
私たちは、技術的な作業を監督する専任チームを設立し、安全に関する意思決定のための運用体制を構築します。準備チームは、フロンティアモデルの能力の限界を調査し、評価を実行し、レポートを統合するための技術的な作業を推進します。この技術的な作業は、安全なモデルの開発とデプロイのための OpenAI の意思決定に情報を提供するために重要です。すべてのレポートを確認し、リーダーシップと取締役会に同時に送付するために、クロスファンクショナル(縦割りのない)安全アドバイザリーグループを作成しています。意思決定者はリーダーシップですが、取締役会は決定を覆す権利を持っています。
We will develop protocols for added safety and outside accountability. The Preparedness Team will conduct regular safety drills to stress-test against the pressures of our business and our own culture. Some safety issues can emerge rapidly, so we have the ability to mark urgent issues for rapid response. We believe it is instrumental that this work gets feedback from people outside OpenAI and expect to have audits conducted by qualified, independent third-parties. We will continue having others red-team and evaluate our models, and we plan to share updates externally.
安全性を高め、外部から説明責任を果たすためのプロトコルを策定します。 準備チームは、定期的に安全訓練を実施して、当社のビジネスと企業文化のプレッシャーに対するストレステストを実施します。一部の安全上の問題は急速に発生する可能性があるため、緊急の問題をマークして迅速に対応することができます。OpenAI以外の人々からのフィードバックがこの作業には重要であると考え、資格のある独立した第三者による監査を実施する予定です。他者によるレッドチームのテストやモデルの評価を継続し、外部との情報共有も計画しています。
We will help reduce other known and unknown safety risks. We will collaborate closely with external parties as well as internal teams like Safety Systems to track real-world misuse. We will also work with Superalignment on tracking emergent misalignment risks. We are also pioneering new research in measuring how risks evolve as models scale, to help forecast risks in advance, similar to our earlier success with scaling laws. Finally, we will run a continuous process to try surfacing any emerging “unknown unknowns.”
私たちは、その他の既知および未知の安全リスクの低減に努めます。。 外部関係者やSafety Systemsなどの社内チームと緊密に協力して、実際の誤用を追跡します。また、Superalignmentと協力して、新たなミスアライメントリスクを追跡します。また、モデルのスケールに伴うリスクの進化を測定する新しい研究を先駆けて行い、以前にスケーリング法で成功したように、リスクを事前に予測するする手助けをします。最後に、新たな「未知の未知」を発見するための継続的なプロセスを実施します。
This is a summary of the main components of the Preparedness Framework (Beta), and we encourage you to read the complete version. This framework is the initial Beta version that we are adopting, and is intended to be a living document. We expect it to be updated regularly as we learn more and receive additional feedback. We welcome your thoughts at pf@openai.com.
これは準備フレームワーク(ベータ版)の主要な構成要素の概要です。完全なバージョンをぜひご一読いただくことをお勧めします。このフレームワークは初期のベータ版であり、私たちが採用するものであり、常に進化するドキュメントです。私たちは、さらなる学びや追加のフィードバックを受けて、定期的に更新されることを期待しています。お客様のご意見をpf@openai.comまでお寄せいただければ幸いです。
-
前の記事

【AI用語解説: エンベディング】計算機で言葉を扱うってどうゆうこと? 2024.02.27
-
次の記事

AIアライメントとは?AIの暴走を防ぐための重要なステップ 2024.02.27